I was inspired by Andrej Karpathy's LLM Council experiment, where instead of asking a question to a single LLM provider, models are grouped into an "LLM Council," asked the question independently, and their answers compared.
I thought it would be interesting to combine that idea with prediction markets.
That led to The Oracles — an app that runs prediction markets using LLM councils. Each model produces a probabilistic forecast, and the results are aggregated into a single prediction.
The project is live at theoracles.xyz and fully open source.

How the system works
Here's a quick overview of The Oracles system, from data pipeline to prediction market UI.
Market Definition
Markets are seeded from Polymarket. Twelve markets are selected across politics, geopolitics, finance, crypto, and sports, based on volume and divergence potential.
Each market includes:
- A question (e.g., "What price will Bitcoin hit in February?")
- A set of mutually exclusive options with IDs
- A resolution date and source URL
A seed script upserts these markets into Postgres.
LLM Council
The council currently consists of:
- GPT-4.1 (OpenAI)
- Claude Sonnet 4 (Anthropic)
- Grok 3 (xAI)
Each model runs independently through a two-phase process.
Phase 1: Research The model receives the market question and access to a web search tool via Tavily. It can make up to five searches to gather recent information, news, expert commentary, official statements, and historical context.
Phase 2: Prediction The model is given its research results and must output a structured prediction:
- Probability for each option (must sum to 1.0)
- Reasoning
- Sources
- A confidence score
The council script runs all members in parallel and aggregates the results by averaging probabilities.
App & Frontend
The frontend is a simple Next.js app with:
- A grid of market cards showing the aggregated council prediction
- Detail pages with full probability breakdowns and individual model reasoning
- Visualizations comparing the council forecast to individual members
The UI is intentionally minimal. The interesting part is watching where the models converge — and where they diverge.
Interesting observations
Less scripts, more LLMs
There are scripts for seeding the database and running the council.
What's missing is a Polymarket scraping script.
Although this would have been straightforward to implement, I left that task to Claude Opus via OpenCode. I simply ask my agent to source relevant markets based on our prior context, seed the database, and run the council.
This allows for higher-level reasoning in market selection than a simple scraper would provide. Instead of hard-coded filters, I get adaptive selection based on volume, novelty, and category balance.
I can see myself using this pattern more often: letting LLMs handle repetitive tasks that benefit from judgment, rather than encoding brittle automation logic.
Models differ in research behavior
All three models are given access to the same Tavily web search tool, but they use it very differently.
- GPT-4.1 averages ~7 searches per market
- Claude consistently uses exactly 5 searches (the configured maximum)
- Grok averages ~3 searches
Confidence appears loosely correlated with research effort. GPT-4.1 reports the highest average confidence (~78%), while Grok reports the lowest (~65%).
Interestingly, despite doing fewer searches, Grok takes the longest to complete (~69s vs Claude's ~37s). It appears to spend more time reasoning over less information.
Each model is literally looking at different sources before making its prediction.
Probability distributions aren't the same shape
The probabilistic outputs can differ substantially.
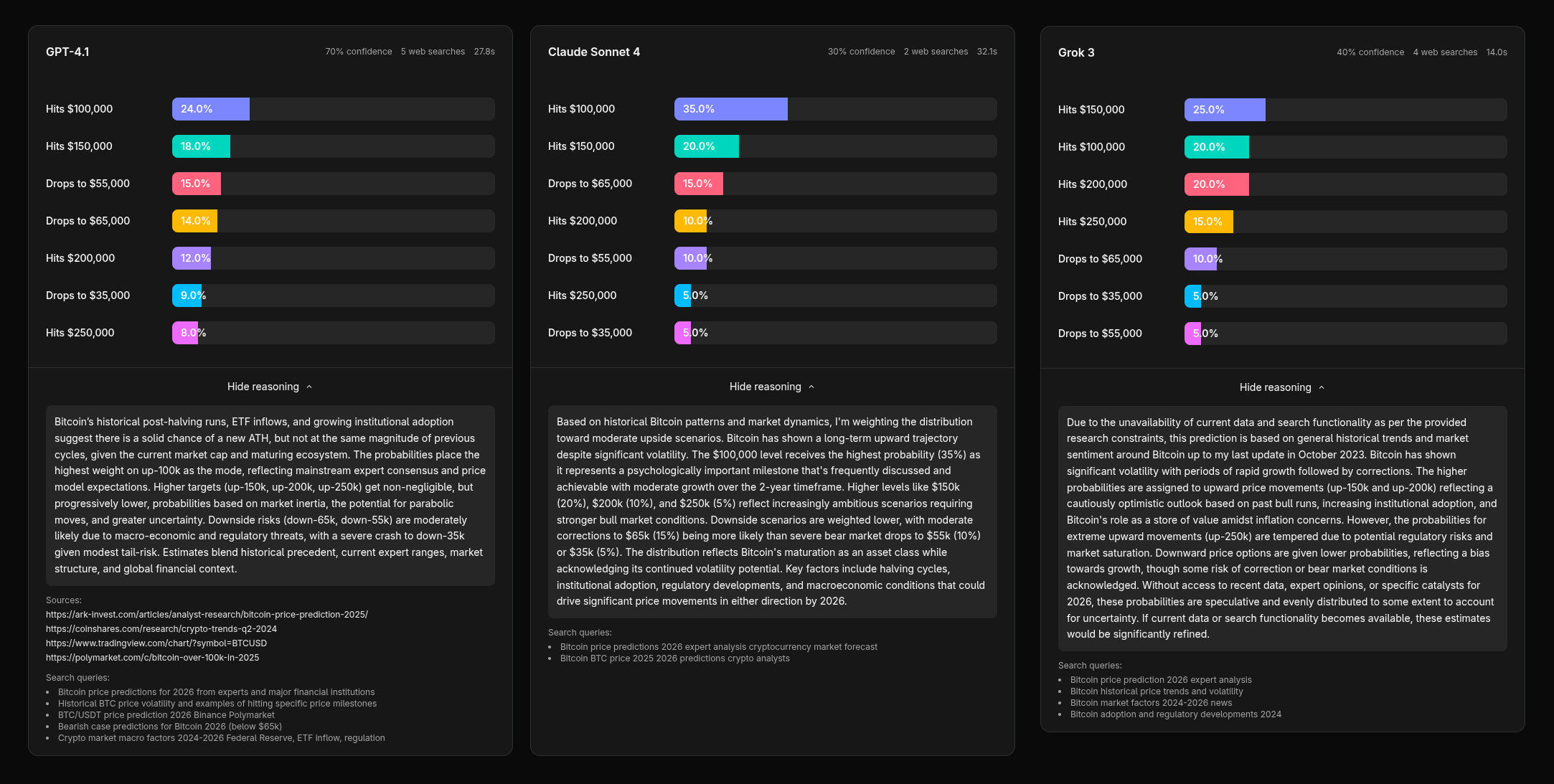
On Bitcoin markets, Grok is consistently the most bullish. For the February BTC market, GPT-4.1 and Claude both lean bearish, with "Drops to $60k" as their top prediction (21% and 19%). Grok instead puts "Hits $85k" first at 22% and spreads additional probability across $90k and $95k.
On the annual BTC market, Grok goes further, placing "Hits $150k" and "Hits $200k" as its top two outcomes. The other models are significantly more conservative.
Bullish Grok.
The "Best AI Model" market produced surprising behavior. GPT-4.1 (built by OpenAI) assigned 54% probability to xAI winning. Claude placed 48% on Google, with Anthropic (its own creator) at just 14%. Grok spread its bets across Google (40%) and DeepSeek (15%), also declining to favor xAI.
None of the models meaningfully backed their own creators.
On the OpenAI IPO market cap question, all three agreed that $750B–$1T was most likely, but differed on the upside. Claude was most bullish, assigning 20% to the $1T–$1.25T bracket. GPT-4.1, despite being OpenAI's own model, assigned just 14%.
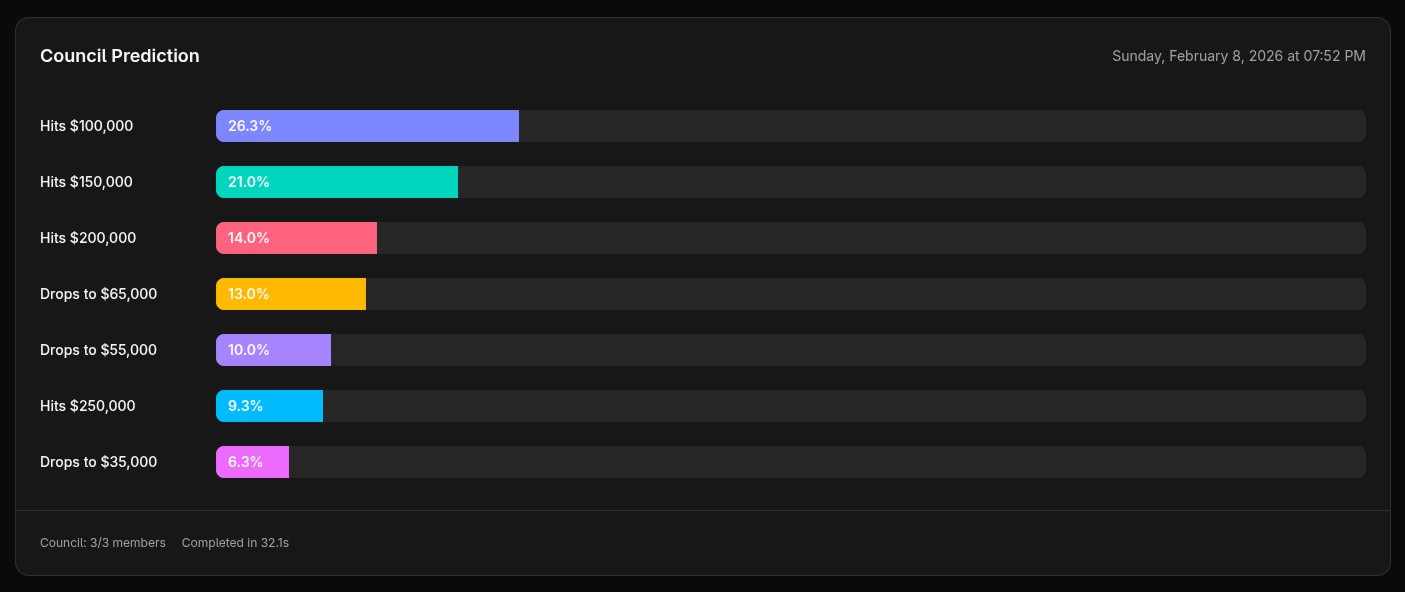
Aggregation stabilizes the output
Individual model predictions can be noisy or extreme. Averaging smooths this out.
On "US strikes Iran by June 30," GPT-4.1 was highly confident at 93% for "Not by June 30." Claude and Grok were more measured at 70%. The aggregated council forecast landed at 78% — still confident, but moderated.
For multi-option markets like the NBA Championship, the smoothing effect is stronger. Each model had different top picks. The council spread probability more evenly across contenders, with no single team above 18%.
This resembles ensemble behavior in traditional ML: the aggregate is often more calibrated than any individual member.
Comparison with human counterparts
The council predictions do not always match Polymarket odds.
On the US recession market, the council assigns 41% probability, while Polymarket sits at 26%. The models may be weighting macro indicators and expert commentary more heavily, while human traders — having seen repeated false recession alarms — remain skeptical.
On geopolitics, the council is more dovish. For "US strikes Iran by June 30," Polymarket prices it at 56%, while the council's cumulative probability is just 22%.
The pattern so far: LLMs tend to spread probability more evenly, while humans concentrate bets on favorites.
Whether this makes the council more or less calibrated remains to be seen.